Low, Kliuchnikov, Schaeffer (LKS) state preparation¶
$$ \newcommand{\ket}[1]{|#1\rangle} \newcommand{\bra}[1]{\langle#1|} \newcommand{\norm}[1]{\left\lVert#1\right\rVert} $$ Here we take a look at a relatively-efficient state preparation routine introduced in arXiv:1812.00954 ⧉ by Guang Hao Low, Vadym Kliuchnikov, and Luke Schaeffer (hence, "LKS" state prep).
As with all state preparation techniques, the goal is the following: given a list of weights $\vec{a} = [a_0, a_1, ..., a_{2^n - 1}]$, prepare the following $n$-qubit state starting from the all-zero state:
$$ \ket{\psi} = \frac{1}{\sqrt{\norm{\vec{a}}_1}}\sum_{i = 0}^{2^n - 1}\sqrt{a_i}\ket{i}$$
What is special about LKS state prep?¶
In spirit, this method belongs to a broader class of state preparation routines known as "Grover-Rudolph" style state preparation, in that it makes use of a cascade of so-called "multiplexed rotations", where the angles you use in those rotations are obtained as a function of the list of weights. This style of state preparation is the same one that WBA's naïve state preparation belongs to.
Multiplexed rotations¶
What differentiates LKS state preparation from naïve state preparation basically comes down to how multiplexed rotations are implemented. The definition of a multiplexed rotation is the following:
$$U = \sum_{x = 0}^{2^n - 1} \ket{x}\bra{x} \otimes e^{2\pi i \theta_x Y}$$
In words: Give me a register encoding index $x$, I will apply a rotation on some other register with angle $\theta_x$ conditioned on that index reg.
Naïvely, decomposing multiplexed rotations looks like this:
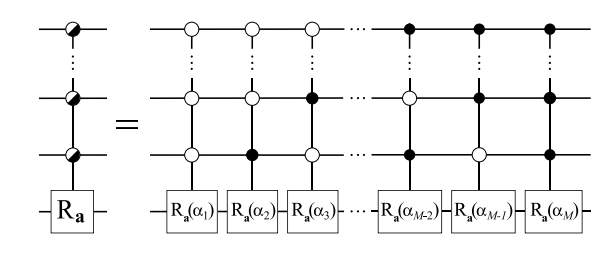
The above circuit has $M$-many $\big(\lceil \log M \rceil\big)$-controlled rotations. If we were to break this up into Toffolis and rotations, we'd be looking at some $\mathcal{\tilde{O}}\big(M \cdot \lceil \log M \rceil \big)$ gate complexity.
The secret sauce to LKS state prep is that by using data-loaders to instead first load $b$-bit representations of these angles coherently, and then do simple single-control rotations on the target state, we can instead get away with a scaling like $\mathcal{\tilde{O}}\big(M + b \big)$. Assuming $b \approx \log M$, we see that we go from a multiplicative scaling to an additive scaling.
LKS multiplexing in action¶
The point of a multiplexor is to coherently apply a variety of rotations by angles $\theta_x$, indexed by the $\ket{x}$ register. If you wanted to do this with data-lookup oracles, roughly speaking you'd have three steps:
- load and index the appropriate $\theta_x$ angle (or some $b$-bit approximation of it we'll call $a_x$).
- conditioned on the bits in this $a_x$ register, apply $b$ singly-controlled rotations that'll add up to a rotation by $a_x$.
- uncompute the data-lookup oracle to return the workhorse bits to their original state.
Let's see how these data-loading-type multiplexors look in code. We can do this by invoking the LKSMultiplexor Qubrick from WBA.
%load_ext autoreload
%autoreload 2
from psiqworkbench import Qubits, QPU
import numpy as np
from workbench_algorithms.utils import gate_efficient_lambda
from psiqworkbench.utils.misc_utils import random_list_vals_n_bit_precision
from workbench_algorithms import (
SelectNaive, # Select imports
SelectOneAnc,
SawtoothSelect,
BinaryTreeSelect,
SwapUp,
DataLookupClean, # QROM imports
DataLookupDirtyNaive,
DataLookupDirtyOptimized,
LKSMultiplexor, # LKS imports
LKSStatePrep
)
# generate some random list of n angles b/w 0 and 180
n = 16
random_angles = np.random.uniform(size=n, low=0, high=180)
random_angles
array([105.53037612, 80.92205542, 48.29793507, 116.77121518,
151.10147405, 61.42417523, 104.42751975, 67.28087014,
24.24047974, 72.50310522, 19.71103878, 118.8497557 ,
23.24495003, 26.95276706, 56.43849289, 101.21925853])
# set up number of qubits for sim
b_of_p = 8 # just choose some bits of precision
lambda_val = 2
num_idx = int(np.ceil(np.log2(len(random_angles))))
num_tgt = 1
num_qrom_anc = b_of_p * lambda_val
num_qubits = num_idx + num_tgt + num_qrom_anc
# set up QPU and Qubits register
qc = QPU()
qc.reset(num_qubits)
idx = Qubits(num_idx, 'idx', qc)
tgt = Qubits(num_tgt, 'tgt', qc)
(idx | tgt).write(0)
# instantiate sub-Qubricks
select = SelectNaive()
swap_up = SwapUp()
qrom = DataLookupClean(select=select, swap_up=swap_up)
# instantiate LKS Multiplexor and call it
lks_mplx = LKSMultiplexor(qrom=qrom, gate=qc.ry)
lks_mplx.compute(idx, tgt, random_angles, b_of_p, lambda_val)
# draw the thing
qc.draw()

Things to note:¶
- Indeed, above you can see that first we load some data using a $\text{QROM}$, where we load the bit values onto the
b_of_p-bit register labeledclean(and we usedjunkas some extra workhorse qubits), then we applyb_of_psingle-qubit RY rotations, with each rotation being conditioned on a significant bit of the loaded angle, and then we uncompute the data-loader.- Note: the data-loader uncomputation notably looks very different from the compute portion; this is because QROMs have a special efficient uncompute.
- The
LKSMultiplexortakes two arguments at instantiation: a data-loaderQubrick, and what type of gate is being multiplexed. In this case (and for state prep), an $\text{RY}$ rotation. - The
computemethod takes an index register, a target register for the rotations, the list of values we are loading, the bits of precision to represent those values at, and a $\lambda$ value, which is the tunable knob used in QROMs to trade off between gates and qubits. This $\lambda$ defaults toNone, in which case the Qubrick `will determine the gate-optimal $\lambda$ to use.
I should note that the above multiplexor can take any variation of a data-lookup oracle; we could use dirty $\text{QROMs}$ which borrow already-allocated qubits, the $\text{QROMs}$ themselves can be made up of any number of choices for $\text{SELECT}$, etc. Below I'll execute another LKS multiplexor for the same input angles and bits of precision which makes use of more complex variations of these subroutines:
# set up number of qubits
num_idx = int(np.ceil(np.log2(len(random_angles))))
num_tgt = 1
num_select_anc = num_idx
num_clean_qrom_anc = b_of_p
num_dirty_qrom_anc = b_of_p * (lambda_val - 1)
num_qubits = num_idx + num_tgt + num_clean_qrom_anc + num_dirty_qrom_anc + num_select_anc
# set up QPU and Qubits register
qc = QPU()
qc.reset(num_qubits)
idx = Qubits(num_idx, 'idx', qc)
tgt = Qubits(num_tgt, 'tgt', qc)
dirty = Qubits(num_dirty_qrom_anc, 'dirty', qc)
# set some random state, and then write all qubits except the dirty reg to zero
# this ensures we're starting the dirty reg in some arbitrary state (i.e. truly "dirty")
qc.set_random()
qc.write(0, ~dirty.mask())
# instantiate sub-Qubricks
select = BinaryTreeSelect()
swap_up = SwapUp()
qrom = DataLookupDirtyOptimized(select=select, swap_up=swap_up)
# instantiate LKS Multiplexor and call it
lks_mplx = LKSMultiplexor(qrom=qrom, gate=qc.ry)
lks_mplx.compute(idx, tgt, random_angles, b_of_p, lambda_val)
# draw the thing
qc.draw()

If you zoom in/squint really hard, you should see that despite the circuit looking very different, we're actually still doing the same exact thing: using a $\text{QROM}$ to load some $b$-bit representation of some angles, applying $\text{RY}$ rotations, and then uncomputing the $\text{QROM}$.
Back to state preparation¶
So far I've gotten into the magic behind LKS multiplexors; how do we get state prep from this? Well, just as in naïve state preparation, we can prepare some desired state with a cascade of multiplexed $\text{RY}$ rotations:
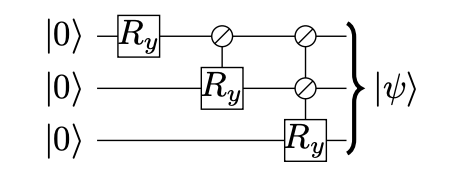
All we're going to do differently now is use the LKS multiplexors detailed above every time we see an $\text{RY}$ rotation in the diagram. Let's work through an example using LKSStatePrep:
# generate a list of random weights
n = 16
weights = np.random.uniform(size=n)
weights
array([0.82887078, 0.34147661, 0.66884771, 0.98851905, 0.30410414,
0.18631797, 0.79954676, 0.32402829, 0.99362488, 0.89564774,
0.3684197 , 0.46461568, 0.72468592, 0.30907587, 0.73934173,
0.63456932])
# set up number of qubits for the sim
b_of_p = 10
lambda_val = gate_efficient_lambda(len(weights) // 2, b_of_p) # only computing here to determine size of the sim
num_prep = int(np.ceil(np.log2(len(weights))))
num_qrom_anc = b_of_p * (lambda_val - 1)
num_qubits = num_prep + num_qrom_anc + b_of_p
# set up QPU instance and Qubits regs
qc = QPU()
qc.reset(num_qubits)
qbits = Qubits(num_prep, 'qbits', qc)
# set up sub-Qubricks
select = SelectNaive()
swap_up = SwapUp()
qrom = DataLookupClean(select=select, swap_up=swap_up)
mplxr = LKSMultiplexor(qrom=qrom, gate=qc.ry)
mplxr_kwargs = {"bits_of_precision": b_of_p}
# instantiate state prep routine and execute circuit
lks_prep = LKSStatePrep(weights, mplxr)
lks_prep.compute(qbits, **mplxr_kwargs)
# draw the thing
qc.draw()

We've run the circuit. Now we can compare the resulting probabilities with the expected result. Remember that we are preparing a finite-bit approximation of the weights, thus, we cannot compare directly. Instead, we can calculate the difference between the resulting probabilities and the input weights, and make sure the differences do not violate any known bounds.
In particular, we will make sure the differences per term and the overall absolute difference do not violate the bounds given in Appendix D in the LKS paper ⧉.
Per term, we need to satisfy the following:
$$\vert p_{\text{calculated}, i} - p_{\text{expected}, i}\vert \leq \frac{2 \pi}{b}$$
For the total difference, we must satisfy:
$$\sum_{i=0}^{2^n - 1}\vert p_{\text{calculated}, i} - p_{\text{expected}, i}\vert \leq 2^n \cdot \frac{2 \pi}{b}$$
We can grab the resulting probabilities in WB by using the peek_read_probability method:
# grab probability of each basis state in the `qbits` register
probs = []
for i in range(len(weights)):
probs.append(qbits.peek_read_probability(i))
Recall that we load normalized states, so first normalize the weights for the check:
norm = sum(weights)
weights = [weight / norm for weight in weights]
# calculate the differences per term, and the total difference
diffs = [abs(probs[i] - weights[i]) for i in range(len(weights))]
calculated_eps = sum(diffs)
# assert they are within the range given in appendix D
expected_eps_per_term = 2 * np.pi * 2**(-b_of_p)
expected_eps = expected_eps_per_term * len(weights)
for diff in diffs:
assert diff <= expected_eps_per_term
assert calculated_eps <= expected_eps
You can further convince yourself that this works by printing the resulting state vector (using qc.print_state_vector()) and comparing to the (normalized and square-rooted) list of weights; you should find that if you ramp up b_of_p, the resulting state vector looks more and more like the processed weights, and likewise, if you crank it down, the state vector should look less and less like the weights.
# print the state on the QPU
qc.print_state_vector()
# print the normalized and square-rooted weights
weights = [np.sqrt(weight) for weight in weights]
weights
|qbits|?> |0|.> 0.294644+0.000000j |1|.> 0.189124+0.000000j |2|.> 0.264465+0.000000j |3|.> 0.321246+0.000000j |4|.> 0.178609+0.000000j |5|.> 0.139829+0.000000j |6|.> 0.289124+0.000000j |7|.> 0.184331+0.000000j |8|.> 0.322063+0.000000j |9|.> 0.305689+0.000000j |10|.> 0.195911+0.000000j |11|.> 0.220194+0.000000j |12|.> 0.275117+0.000000j |13|.> 0.179584+0.000000j |14|.> 0.277717+0.000000j |15|.> 0.257193+0.000000j
[np.float64(0.29427207768156743), np.float64(0.1888800622635024), np.float64(0.2643438800555365), np.float64(0.3213646922855847), np.float64(0.17824477295714358), np.float64(0.13951889020923505), np.float64(0.2890197852769528), np.float64(0.18399122325558173), np.float64(0.32219356939539484), np.float64(0.30589632293203073), np.float64(0.19619008651614395), np.float64(0.22031931316281367), np.float64(0.2751569899195974), np.float64(0.17969590829065082), np.float64(0.27792540532263377), np.float64(0.25748099318728207)]
(Lots of ) Things to note:¶
LKSStatePreptakes the weights you wish to load and the multiplexorQubrickyou wish to use at instantiation.- The
computemethod takes the qubits you are preparing the state onto, and a number of keyword arguments ⧉ that are relevant to the multiplexor (hence, why I call itmplxr_kwargs). Keyword arguments are Pythondicts that take in some number of keys and associated values. In this case, these include:"bits_of_precision": b_of_p."lambda_val": lambda_val(this will again default to the gate-efficient value if you do not pass anything).
- Instead of manually setting a
lambda_val, I am generating one as a function of the number of elements in the list I want to load and the bits of precision I am using to represent the angles via the WBA utility functiongate_efficient_lambda(num_elements, b_of_p). The reason for this is that each of the QROMs in the cascade of multiplexors used for state prep will have a different optimal value. And in fact, if we choose alambda_valthat works for one QROM but is too big for another, then we will get a bit-indexing error. When doing state prep, it is better to default toNone, in which case eachlambda_valfor each QROM will be computed on-the-fly.
Final big example¶
For the sake of completion, below I provide some code that lets you mix and match the various sub-Qubricks that make up LKSStatePrep just so you can see some (potentially) wild circuits. Be warned: because the various options use very different numbers of qubits, there's a lot of pre-amble to setting up the executable circuit properly.
# choose your SELECT
# select = SelectNaive
# select = SelectOneAnc
select = BinaryTreeSelect
# select = SawtoothSelect
# choose your QROM
qrom = DataLookupClean
# qrom = DataLookupDirtyNaive
# qrom = DataLookupDirtyOptimized
# generate a list of random weights (choose your favorite n, b, and lambda_val)
n = 25
b = 5
weights = np.random.uniform(size=n)
norm = sum(weights)
lambda_val = gate_efficient_lambda(len(weights) // 2, b)
weights
array([0.60093618, 0.81684748, 0.88397849, 0.19948378, 0.82016866,
0.20296022, 0.32209254, 0.76110406, 0.66294125, 0.63065808,
0.18436594, 0.25973206, 0.94143079, 0.54765213, 0.88411396,
0.56102532, 0.91162288, 0.23828153, 0.64318913, 0.57790401,
0.71910509, 0.71445333, 0.04011462, 0.51227364, 0.64989736])
# set up number of qubits
num_prep = int(np.ceil(np.log2(len(weights))))
if select.__name__ == "SelectOneAnc":
num_select_anc = 1
elif select.__name__ in ["BinaryTreeSelect", "SawtoothSelect"]:
num_select_anc = num_prep
elif select.__name__ == "SelectNaive":
num_select_anc = 0
if qrom.__name__ == "DataLookupDirtyNaive":
num_dirty = 3 if lambda_val == 1 else b * lambda_val
num_clean = 0
elif qrom.__name__ == "DataLookupDirtyOptimized":
num_dirty = 3 if lambda_val == 1 else b * (lambda_val - 1)
num_clean = 0
else:
num_dirty = 1
num_clean = b * (lambda_val - 1)
num_qubits = num_prep + b + num_dirty + num_select_anc + num_clean
# set up QPU instance and qubits
qc = QPU()
qc.reset(num_qubits)
qc.write(0)
qbits = Qubits(num_prep, 'q', qc)
dirty_reg = Qubits(num_dirty, 'dirty', qc)
# set dirty qubits to random init state, write the rest to zero
qc.set_random()
qc.write(0, ~dirty_reg.mask())
# set up sub-Qubricks
swap_up = SwapUp()
select = select()
qrom = qrom(select=select, swap_up=swap_up)
mplxr = LKSMultiplexor(qrom, qc.ry)
mplxr_kwargs = {"bits_of_precision": b} # do not set a lambda val here as each QROM should choose its own
# execute circuit
prep = LKSStatePrep(weights, mplxr)
prep.compute(qbits, **mplxr_kwargs)
# draw the thing
qc.draw()

# process results and compare with expected results
processed_weights = [float(abs(weight)) / norm for weight in weights]
probs = []
for i in range(len(weights)):
probs.append(qbits.peek_read_probability(i))
diffs = [abs(probs[i] - processed_weights[i]) for i in range(len(processed_weights))]
calculated_eps = sum(diffs)
expected_eps_per_term = 2 * np.pi * 2**(-b)
expected_eps = expected_eps_per_term * len(processed_weights)
for diff in diffs:
assert diff <= expected_eps_per_term
assert calculated_eps <= expected_eps
for prob, processed_weight in zip(probs, processed_weights):
print('~~~~~~~~~~~~~~~~~~~~~~~~')
print('prob: ', prob)
print('processed weight: ', processed_weight)
~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.03912919830654185 processed weight: 0.042063712017463395 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.05809711012734905 processed weight: 0.05717684930227403 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.06526788429731041 processed weight: 0.061875816836127716 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.014600143710048176 processed weight: 0.01396325999262114 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.059441589661998126 processed weight: 0.05740932165270929 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.013296826774185016 processed weight: 0.014206600833825876 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.022451314784791645 processed weight: 0.022545501928876634 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.05028710165139143 processed weight: 0.05327497884315763 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.04210653767403032 processed weight: 0.04640387914593323 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.04210653767403031 processed weight: 0.044144155234137734 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.01217577831589576 processed weight: 0.0129050571274327 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.01807799710495272 processed weight: 0.01818045738660688 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.06712845337217913 processed weight: 0.0658973034896047 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.03692370590017413 processed weight: 0.038333990150711456 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.06217586426563503 processed weight: 0.061885299330050575 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.04187629500671816 processed weight: 0.039270072812048015 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.06466862612933914 processed weight: 0.06381083998855601 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.018475965810823336 processed weight: 0.01667898537176074 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.045647093538002656 processed weight: 0.045021290485237175 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.037497498402159726 processed weight: 0.040451530211280645 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.05024848407331417 processed weight: 0.05033517775929252 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.05024848407331415 processed weight: 0.05000956851515059 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.0030422943811263983 processed weight: 0.0028079015545016167 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.033061513634647176 processed weight: 0.03585760333899893 ~~~~~~~~~~~~~~~~~~~~~~~~ prob: 0.051967701330042214 processed weight: 0.045490846691640566
The end¶
Enjoy!